Thursday, January 12, 2023
Real Time Ruby: Websockets, SSE or Long Polling?
Since Web 2.0, the web has been moving towards a more interactive experience. In 2004 we got AJAX requests (a short for Asynchronous Javascript And XML). AJAX allowed us to make requests to the server and update pages w/out reloading. This changed the web and started the era of web applications. But AJAX is not real time feature, so there had to be something else to give us ability for pushing updates to the clients as soon as we got them. This is where WebSockets, Long Polling and Server Sent Events come in. In this article we’ll go over the differences between these technologies, find out their pros and cons and see how we can use them specifically with Ruby apps.
What is Real Time?
Real time means that the data is updated as soon as it is available. For example, if you are chatting with someone, you want to see the messages as soon as they are sent. If you are playing a game, you want to see the changes as soon as they happen. If you are watching a live stream, you want to see the video as soon as it is available. This is what we call real time.
So what options do we have out their to implement real time features in our Ruby apps?
Short Polling
The first option is to use short polling. Short polling is the simplest way to implement real time features. It is also the most inefficient way. Let’s take a look at how it works:
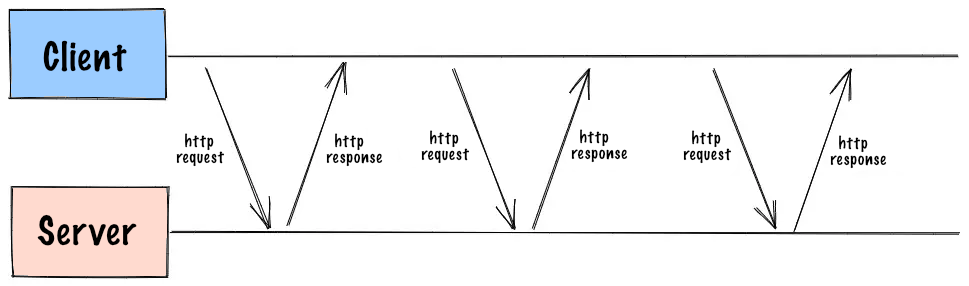
As you can see, the client makes a request to the server, and server responds with the info it has at the moment, the connection is closed. This process repeats after some predefined interval. It is simple, so can be implemented with few lines of JS code (utilizing AJAX requests), but it is also inefficient. The client has to make a request every time it needs to check for updates, and if you have lots of clients constantly sending requests to the server, obviously it can consume lots of server resources. This is not a good solution for real time features and, since we have some better options, it’s not advisable to use short polling.
Websockets
WebSockets is a bi-directional real time technology. It is a protocol that allows the client and the server to communicate with each other. The thing you need to keep in mind is that websockets are not using HTTP protocol, so you can’t use them with Rails controllers. Websockets is a separate protocol on top of TCP, so it’s a long living TCP connection. You need to use a separate server for handling websockets. There are several options for this, which we’ll discuss further in the article. Let’s take a look at how websockets work:
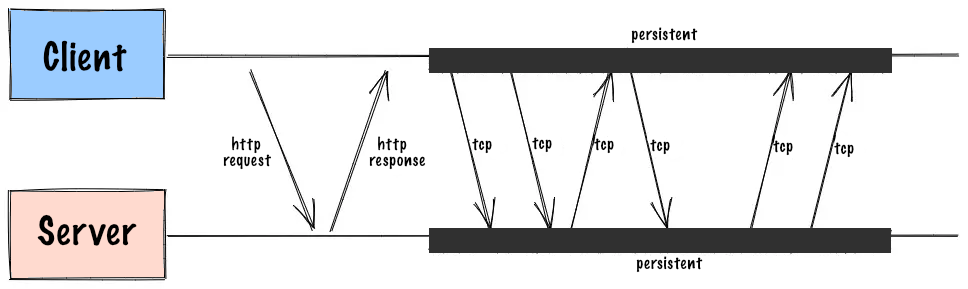
Pros:
- Websockets are bi-directional. This means you can send messages from server to client and from client to server.
- Can transfer both text and binary data. Basically you can send anything using websockets.
- Websocket connection is a long living connection. This means that you don’t have to make a request every time you need to check for updates. So there is no headers overhead, which reduces data loads being sent to the server.
- Websockets are fast and efficient
Websockets are stateful
One more thing you should know about Websockets is that they are stateful, this means that connection between client and server should store some state. In other words the client should know about the server and vice versa. However web frameworks are historically stateless, meaning once web server got the request, it processes it and sends the response. After that the connection is closed and the server forgets about the client.
The Rack protocol is the specification for how web servers and apps should communicate in the Ruby world. Rack offers a straightforward, modular, and flexible interface for creating Ruby web applications. An application is an object that replies to the call method, passing the environment hash as a parameter, and returns an Array with three components. Every HTTP request will result in a call to it. The “environment” is a massive hash that includes all the parameters, including the HTTP method, the requested path, the request headers, etc. It must return an array of the form [‘200’, {‘Content-Type’ => ’text/html’}, [“Hi, I’m a Rack app”]]. From the largest Rails site to a single method Sinatra project, almost every Ruby app that delivers anything over HTTP is using Rack.
Rack makes it straightforward to implement simple web servers, but has a downside: it works on the level of a single HTTP request. Every common Ruby server is using a process per request/thread per request model.
So how can we implement websockets in a stateless framework like Rails? The answer is ActionCable.
ActionCable
![]()
Rails 5 was releasedIn 2016 along with ActionCable, which is a framework for implementing real time features in Rails apps. Now it’s a part of Rails, and is installed with any new Rails app, unless you explicitly disable it.
Not all Ruby web servers are ready to work with websockets out of the box, this is why Rails 5 was used to switch the default web server from Webrick to Puma. And even then Puma had it’s own issue, and was restricted by 1024 open websocket connections per process, which can be achieved really fast in apps using websockets.
The reason behind that was that Puma Reactor was depending on IO.select internally to loop through all the connections. This approach was not only inefficient but also was limiting the number of open connections. This was fixed only in 2019 with Puma v4, when it switched from select to epoll for Linux and kqueue for FreeBSD.
According to JetBrains research 60% of Ruby developers use Puma as web server for their apps, but it’s still a question how many of them are using Puma versions higher than v4.
For now lets assume you’re working with up to date Rails, Puma and ActionCable versions. But how does ActionCable handles the stateful nature of websockets?
Rack Hijack
To bypass the stateless nature of Rails framework ActionCable is using Rack Hijacking API to hijack the connection and turn it into a websocket connection. This Rack feature allows apps to take control over the connection and perform operations on it. This means that the connection is not closed after the request is processed, the server keeps it open and can use it any time it has some new data to send to the client.
There are two modes for Rack Hijacking API:
- A full hijacking API, which gives the application complete control over what goes over the socket. In this mode, you’re fully responsible for sending both headers and response body and closing the socket. The application web server doesn’t send anything over the socket, and lets the application take care of it. you can perform a “full” hijack by calling env[‘rack.hijack’].call, after which the socket will be accessible in env[‘rack.hijack_io’]
- A partial hijacking API, which gives the application control over the socket after the application server has already sent out headers. This mode is mostly useful for streaming. It’s working by assigning a lambda to the rack.hijack response header. The server sends out headers and then this lambda gets called and receives the socket as an argument. As with partial hijacking you’re still responsible for closing the socket.
So how Rack Hijacking can be used in practice? Let’s take a look at a simple example using threaded server like Puma, which is using thread per request model. Puma threads are reused from a single thread pool with a default maximum size of 16 threads. Additional requests will have to wait until any of the threads sends the response and becomes available.
If we want to perform socket hijacking, we have to store the connection in a globally available Array, this way we will release Puma thread and make it available for other incoming requests, but also this will keep the connection open and not closed by the garbage collector. The connection will stay open as long as it’s present in the Array. Here goes an example using partial hijacking:
require 'puma'
require 'rack'
connections_storage = []
app = lambda do |env|
response_headers = {}
response_headers["Transfer-Encoding"] = "binary"
response_headers["Content-Type"] = "text/plain"
response_headers["rack.hijack"] = lambda do |io|
connections_storage << io
end
[200, response_headers, nil]
end
Then you can use a separate thread to iterate over the connections storage array and do anything with each connection (e.g. upgrade to websockets protocol) without blocking Puma threads from the thread pool used for incoming HTTP requests.
How does ActionCable work?
ActionCable server is by default mounted to your Rails app and is available at /cable path. It’s a Rack application, which is using Rack Hijacking API to hijack the connection and turn it into a websocket connection. It also can be used as a standalone server, if you want a separation of concerns and completely independent scaling. However, you should keep in mind, that in the case of standalone ActionCable server, deployment becomes more complex and cookies can’t be reused, so you’ll have to deal with authentication for websockets separately.
ActionCable comes with client side library, which handles the connection automatically and can recover subscription. It is using pings from the server to client, each 3 seconds the server is sending a ping to the client, and if the client doesn’t receive pings for 6 seconds, the client will try to reconnect.
To synchronize between processes ActionCable is using Redis Pub/Sub features (or Postgres), this way it can send messages to clients connected to different servers. So how does ActionCable sends messages from server to clients?
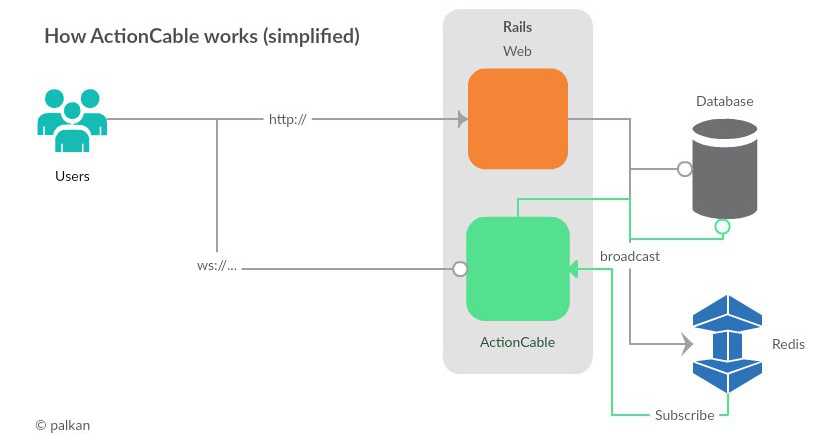
Basically, when server wants to send a message it’s using broadcast method, to put the task into Redis, then ActionCable code is triggered in each Rack process and it’s sending the message to the client using the list of hijacked connections.
When ActionCable sends a message from the client to the server, ActionCable callbacks are fired in the Rack process on data receive. Those callbacks are fired in processes where we have subscribed clients.
Looks like this is a win-win situation, we have a stateful protocol, which is working with stateless framework, and we have a way to synchronize between processes. Real-time was never so easy, right? Well, not exactly.
ActionCable performance
Other than issues mentioned above, there are also some issues related to ActionCable’s performance:
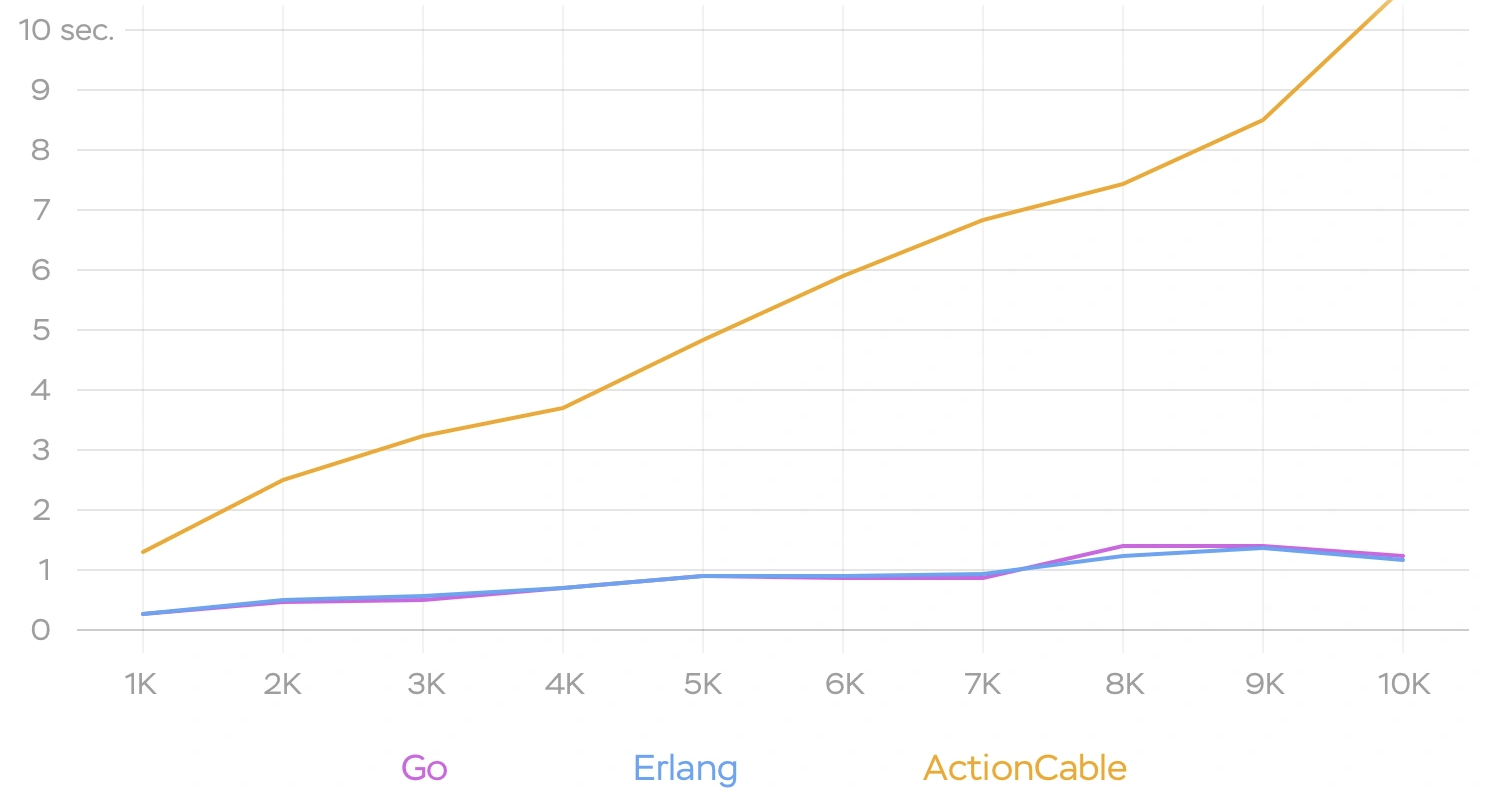
- ActionCable server is written in Ruby, so when you have thousands of connections it’s going to be not so performant as one would expect. For instance if you have 10k connections and want to broadcast the same message to all of them, the last client will receive it with roughly 10 seconds delay, which is not acceptable for real-time applications. So the more clients you have the more time it takes to broadcast a message:
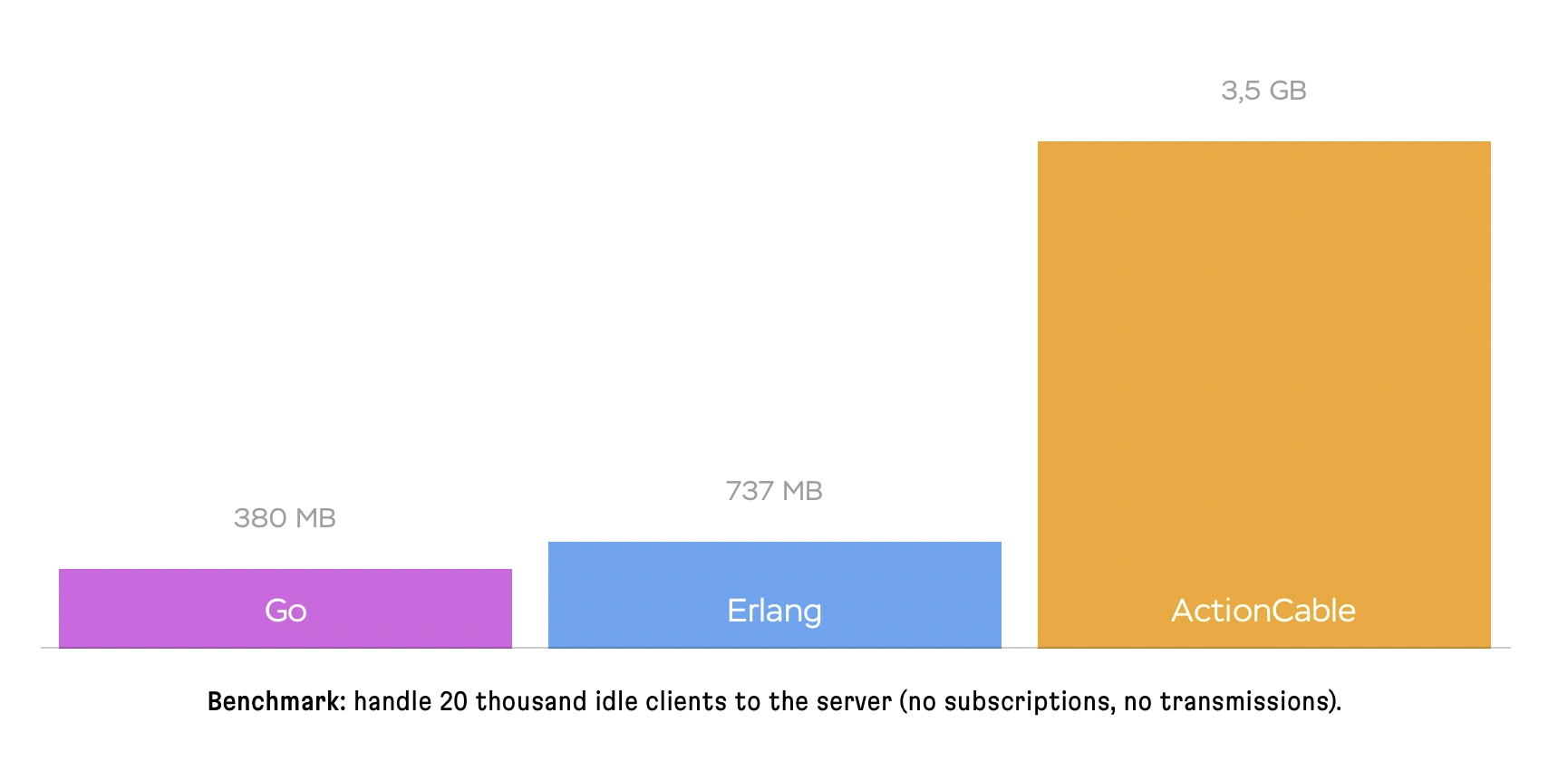
- Another metric here will be the memory usage, since ActionCable is using Ruby and Rails, it’s going to be more memory hungry than servers written in Go or Erlang. One idle connection will consume roughly ~190Kb of RAM, so for 20k connections you will have the following results:
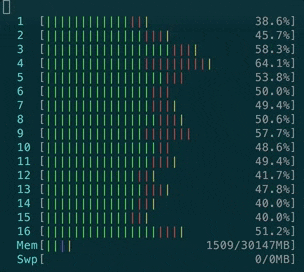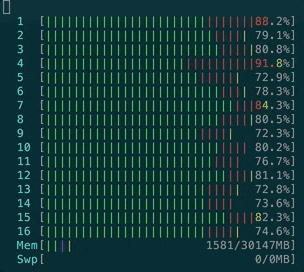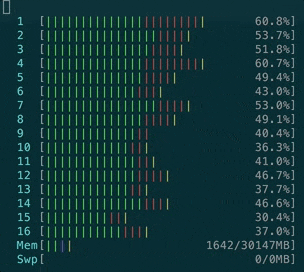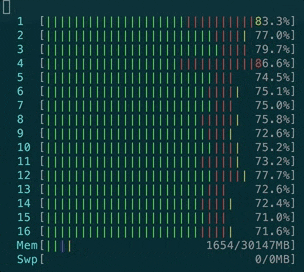
- ActionCable CPU loading during messages processing is extensive. Here’s how CPU reacts to a case when we have 1k clients connected and 40 of them are sending a message to a server, which is then re-transmitted to all clients:
Most likely, if your project reached 10k websocket connections with ActionCable, you better switch to AnyCable.
AnyCable
AnyCable is a project, created by Vladimir Dementyev from Evil Martians, which allows you to use any WebSocket server (written in any language) as a replacement for your Ruby websockets server (such as Faye, Action Cable, etc).
AnyCable is fully compatible with ActionCable javascript client, so you can use it as a drop-in replacement for ActionCable server. The main goal of AnyCable is to make work with websockets more performant and scalable, which is achieved since the two currently available server implementations are written in Erlang and Go, which are more performant and memory efficient than Ruby. AnyCable is also using Redis Pub/Sub under the hood.
How does AnyCable work?
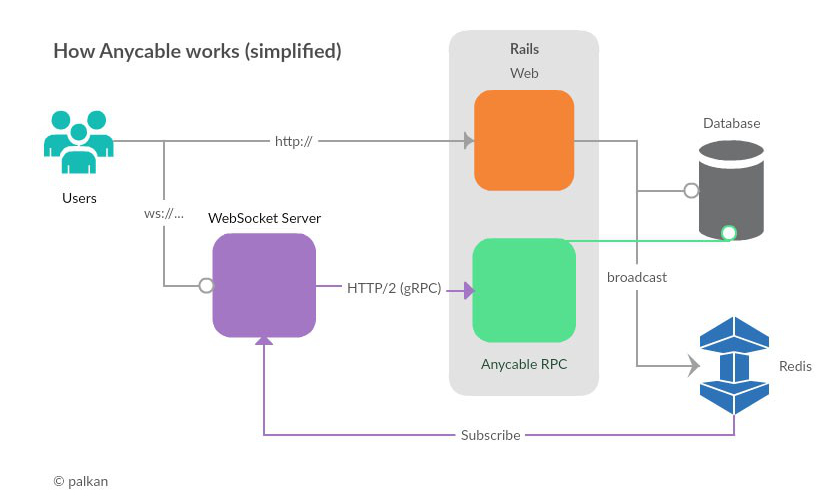
As with AnyCable you have a standalone Go/Erlang websockets server, it also uses an RPC (gRPC) server to connect a Rails app and Websockets server. It’s also using Redis Pub/Sub to proxy messaged published by your application to WebSocket server which in its turn broadcast messages to clients:
AnyCable performance
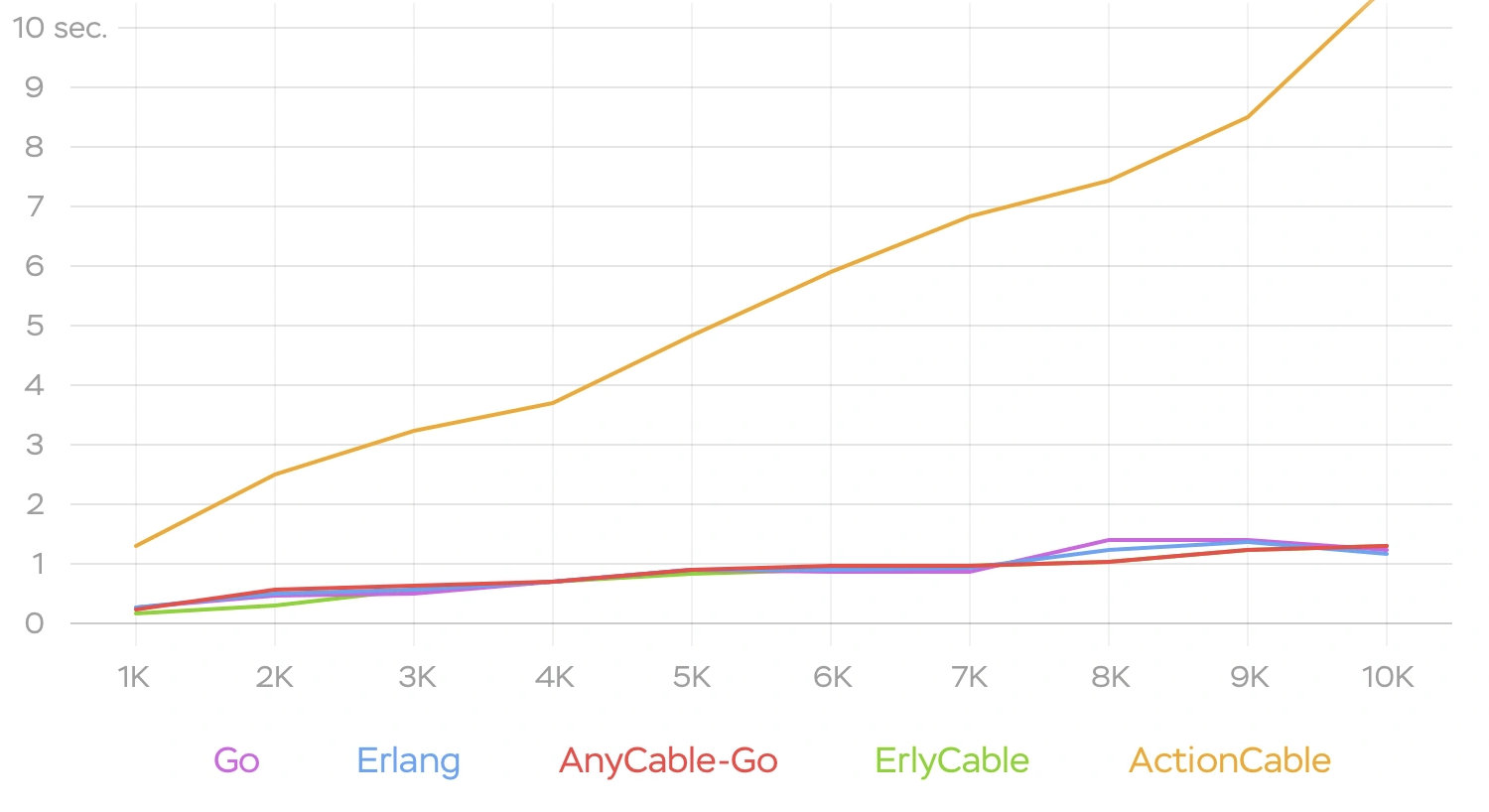
- AnyCable handles message transmission much better, for 10k clients you’ll be getting roughly 1s rtt:
- Since with AnyCable memory intensive operations (e.g. storing connection states and subscriptions maps, serializing data) are moved to a standalone Websockets server, memory usage of AnyCable is significantly lower:

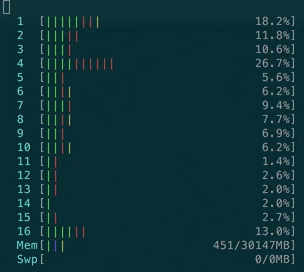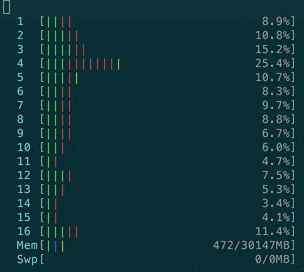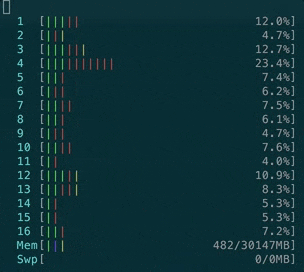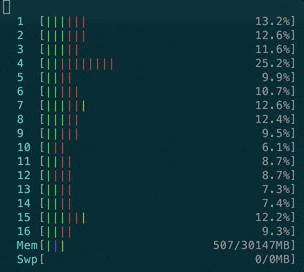
- CPU usage is also far less intensive than with ActionCable:
No more ActionCable issues?
Well, not exactly. Both AnyCable and ActionCable are still having some limitations, which can be critical for some projects:
- No message queues support/state can be lost. Every time your client has to reconnect to server, because connection was lost, new connection will be established and all previous state will be lost. This means any message sent during the connection was lost will be lost as well. There’s no way of catching up on what was published while client was reconnecting
- No message ordering guarantee. Published messages do not have identifiers so it is impossible for the client to process messages in order. This can be a problem if you’re using ActionCable or AnyCable to build a chat app, for example.
- No guarantee of delivery and no success confirmation. There is no confirmation of success or failure for the client when publishing messages to the server. If user is chatting with a group of people, this can be critical to update the user interface on failure, or retry message sending.
- No fallback mechanism support. If websocket connection was not established for some reason, there’s no way to fallback to long polling or any other transport. As the result the feature may become completely unusable for some users.
- 200-255 maximum websockets connections for all browser tabs. This means that your browser will be able to establish only 200 websockets connections (255 for Chrome) and if you have more tabs open they won’t have websockets connections established. This might be not a big deal for most of the users, but good to keep in mind. It’s not a limitation of ActionCable or AnyCable, but of the browsers themselves.
- Websockets load balancing. When implementing real-time features with websockets you’ll have to deal with load balancing. First your load balancer should support websockets (e.g. AWS Elastic Load Balancer does not support websockets, so you have to use Application Load Balancer instead). Second, you need to configure your load balancer, to be sure that websocket connections are distributed to all instances.
- It’s hard to monitor websockets loading In general, it is not easy to monitor/profile the load specifically on websockets in real-time. One need to do load testing in advance using the tools available for this, see what happens in terms of resource consumption with the expected number of clients. But in real time you can’t know how loaded are ActionCable workers, there are no statistics. AnyCable has some metrics to understand that it’s time to scale.
Although Websockets is the only protocol which allows bi-directional communication, it’s not the only way to implement real-time features. There are other options, which are more suitable for some use cases.
Long Polling
Basically Long Polling is an HTTP connection, which stays open for some period of time. Similar to short polling, the client makes a request to the server, and server responds with the info it has at the moment, or, if there are no updates ready, it keeps the connection open and waits for some predefined period of time. If the server gets an update during this time interval, it sends it to the client and closes the connection. If the server doesn’t get an update before timeout threshold is reached, it still closes the connection. Then the client makes another request and the process is repeated.
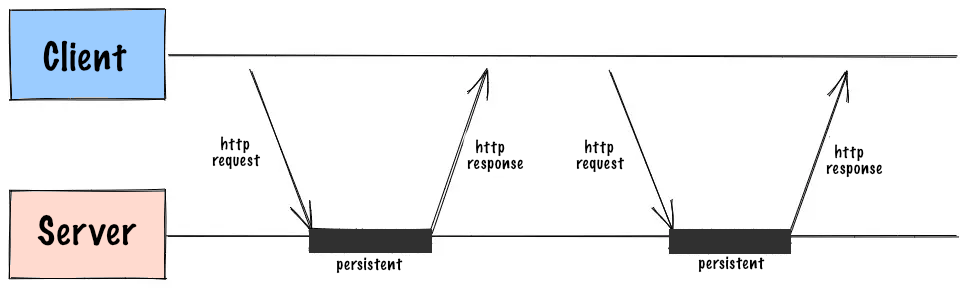
Long Polling was the first kind of real-time technology to be implemented in browsers and it’s supported by all major browsers, but it still has some drawbacks. First of all, it is not a true real time technology. The client has to make a request every time it needs to check for updates, so it is not as efficient as WebSockets or Server Sent Events. Some of the other drawbacks are:
- Long Polling is not a bi-directional channel. The client can’t send any data to the server through the long polling connection.
- Header Overhead. Every long poll request and response is a complete HTTP message and contains a full set of HTTP headers in the message framing, which are not needed for the actual data transfer. For small, infrequent messages, the headers can represent a large percentage of the data transmitted.
- Maximal Latency. After a long poll response is sent to a client, the server needs to wait for the next long poll request before another message can be sent to the client. This means that while the average latency of long polling is close to one network transit, the maximal latency is over three network transits.
- Thread Blocking. Long polling is a blocking operation, which means that the server thread is blocked until the client receives response and closes connection.
- HTTP/1 maximum connections limit. Which makes long polling hardly usable when opening multiple tabs, as the limit is per browser/domain and is set to a very low number - 6.
HTTP/2
HTTP/2 was released in 2015 as a major revision to the HTTP/1.1 protocol, which main goal was to fix HTTP/1 performance issue. HTTP/2 achieved reducing latency by enabling multiplexing (for requests and responses), headers compression (to minimize overhead) and allowing server push.
HTTP/2 has no effect on the application semantics of HTTP. All fundamental ideas, including HTTP methods, status codes, URIs, and header fields, remain unchanged. Instead, HTTP/2 adjusts how data is formatted (framed) and transferred between the client and server, which both handle the entire process, and hides any complexity from our applications under the new framing layer. Consequently, all existing apps can be given unchanged.
So the HTTP/2 feature, which makes both Long Polling and SSE usable again, is multiplexing. Multiplexing allows the client to send multiple requests over the same connection, which means that the client can have multiple requests running simultaneously, and this will take only one single opened TCP connection to the server. This is a huge improvement over HTTP/1.1, where each request was using a separate TCP connection.
Using long polling over HTTP/2 solves the problem of connections limit. Multiplexing a single HTTP/2 connection across tabs speeds up page loading in new tabs and considerably lowers the cost of long polling from a networking perspective. Then why can’t we multiplex our websockets connections the same way? As we already mentioned earlier, HTTP/2 and WebSockets are different protocols, so it is not possible to tunnel one over the other.
HTTP/2 makes Long Polling a good alternative to Websockets, especially if bi-directional communication isn’t really needed and if one is not concerned about the feature to be the real “real-time” (i.e. if some delay is acceptable).
Basic long polling functionality can be definitely implemented from scratch, but if you want something advanced, there is a Ruby gem available, which is packed with features - MessageBus
Messagebus
MessageBus implements a Server to Server channel based protocol and Server to Web Client protocol (using polling, long-polling or long-polling + streaming). MessageBus is also using Rack Hijack interface, which allows it to handle thousands of concurrent long polling connections and not block server threads. It runs as middleware in your Rack (or by extension Rails) application and does not require a dedicated server. It’s also using Redis pub/sub to synchronize between instances.
MessageBus is production ready, as it was extracted out of Discourse and is used in thousands of production Discourse sites at scale. Similar to ActionCable, MessageBus has a client-side library, which provides an API to interact with the server. It is a simple ~300 line JavaScript library, which is easy to understand and modify. You can include it’s source file on a page or import via asset pipeline. Then in your JS app code you can subscribe to particular channels and define callback functions to be executed when messages are received:
MessageBus.start(); // call once at startup
// how often do you want the callback to fire in ms
MessageBus.callbackInterval = 500;
// you will get all new messages sent to channel
MessageBus.subscribe("/channel", function (data) {
// data shipped from server
});
// you will get all new messages sent to channel (-1 is implicit)
MessageBus.subscribe("/channel", function(data){
// data shipped from server
}, -1);
// all messages AFTER message id 7 AND all new messages
MessageBus.subscribe("/channel", function(data){
// data shipped from server
}, 7);
// last 2 messages in channel AND all new messages
MessageBus.subscribe("/channel", function(data){
// data shipped from server
}, -3);
// you will get the entire backlog
MessageBus.subscribe("/channel", function(data){
// data shipped from server
}, 0);
MessageBus comes with few features which ActionCable and AnyCable lack:
- Message queues. With MessageBus messages are locally sequenced to a channel. In other words, the client can always tell the server at what position the channel is and catch up with old messages. You also can order all of the incoming messages.
- Fallback to short polling. With MessageBus you have a fallback to short polling, and, even though short polling is not something you would want, it still adds reliability to your features. Also, MessageBus is using browsers visibility API, so whenever the tab goes to background and it doesn’t make sense to keep long polling connections open, it fallbacks to a polling with 2 minutes intervals.
- Easy load balancing. With long polling and MessageBus developer doesn’t need to care about load balancing if it’s already working for regular HTTP requests. Just because each time a threshold reached or data is received the connection is closed and next request will be properly balanced at the time it hits the load balancer.
So if you care about messages ordering, or the ability to catch up on the missed messages (while your client was disconnected form the internet), and you’re fine with small delay for message delivery - MessageBus is a great choice to go with. Yes, it doesn’t have a way to send messages from client to server, but instead you can have a reliable way to receive messages with long polling plus you can simply use HTTP POST requests to send data from the client to server. The majority of web applications are still read applications, so not every app needs to send data via websockets.
The return of Server-Sent Events
Server Sent Events have some similarities both to Websockets and Long Polling. Like websockets SSE uses a long-lived connection from client to server, but instead of running it over WS protocol it’s using normal HTTP, similar to Long Polling. Then, browser clients are registering to the event source via the EventSource JS API. The source of the event will be passed to EventSource during instantiation, which will handle connection to the source so clients will get updates sent automatically.
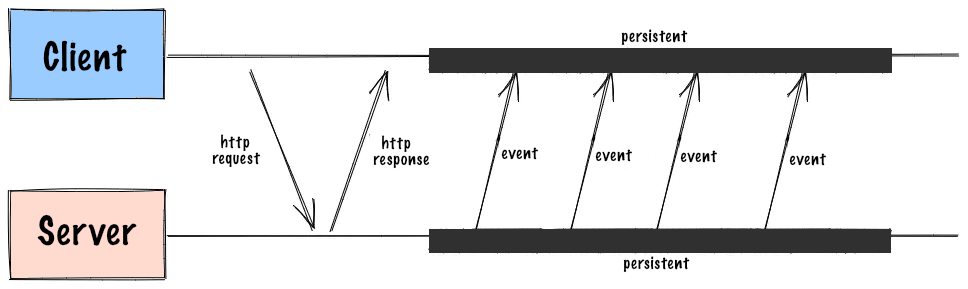
SSE is a simple and lightweight solution, which is supported by all modern browsers (except IE and Edge versions prior to 2020). It does not have header overhead, like long polling, since at the time connection is established it is kept open and does not have to reconnect. It also supports automatic reconnection, and, same as long polling, works over HTTP/2 so it’s pretty efficient and means that they can start functioning without the need for a unique protocol or server implementation. The downside is that it is not bi-directional, so you can’t send messages from the client to the server.
SSE messages are delimited by two lines and have an event id (should be unique), event data (which is the event’s payload) and event name (like a channel name to which one can subscribe on the client side). If messages are including ids, then if SSE connection was lost, the client will send a header Last-Event-ID on a reconnect, so the server could send all the missed messages (during the time connection was lost). So here’s an example of an SSE message:
id: 123\n
event: event_name\n
data: {"sample":"data"}\n\n
Server-Sent Events were hardly usable, just like Long Polling, because of the connection limit. But with HTTP/2, which allows to multiplex multiple requests over the same connection, SSEs are now a viable option for real-time communication. And they’re fairly simple to implement both on the client side, and on the server side.
For the client side, you just need to create a new EventSource object, passing the URL of the server endpoint as the argument. Then you can listen to the message event, which will be fired whenever the server sends a new message:
const es = new EventSource("https://localhost/sse");
es.onopen = e => console.log("EventSource open");
es.addEventListener(
"message", e => console.log(e.data));
// Event listener for custom event
es.addEventListener(
"join", e => console.log(`${e.data} joined`))
Client can also listen to the error events, and can be subscribed to custom events by using addEventListener method (as seen in the example above with join event).
Unfortunately, there are no solutions similar to MessageBus or ActionCable for SSE, but Rails has ActionController::Live module, which allows to stream data from the app controller to the client and is a good starting point for implementing SSEs.
ActionController::Live and threads blocking
When ActionController::Live is included into controller, it allows all actions in the controller to stream data to the client in real time:
class EventsController < ActionController::Base
include ActionController::Live
def index
100.times { response.stream.write "hello world\n" }
response.stream.close
end
end
However, as we discussed earlier, threaded servers are using thread per request model and each request is handled by a separate thread. So, if you have a controller action which is streaming data to the client, it will block the thread. A separate server thread will be used for each SSE connection if they are implemented as in the example code above. The following client won’t be able to connect to the server until there is a free thread while all server threads are busy.
In order to effectively stream data via SSE, one have to use Rack Hijacking API, which will allow to take control over connection and to free server threads for handling other incoming requests. To achieve that, first you need to take control over connection using Rack Hijacking API, then you need to create a new thread to process the connection, and return from controller informing the web server that request was had been processed and it can release the thread to process new requests. The following code snippet shows how to do that:
class MessagesController < ActionController::Base
def create
@message = Message.create(msg_params)
# using Redis Pub/Sub to broadcast messages on the "messages.create" channel
RedisClient.publish('messages.create', @message.to_json)
end
def events
response.headers["Content-Type"] = "text/event-stream"
# moving connection to be porocessed in a separate thread
response.headers["rack.hijack"] = lambda do |io|
Thread.new { (io) }
subscribe_to_messages(io)
end
end
# free up the currently busy thread
head :ok
end
private
def subscribe_to_messages(io)
sse = ActionController::Live::SSE.new(io, retry: 300, event: "messages.create")
redis = Redis.new
# subscribing to the "messages.create" channel
redis.subscribe('messages.create') do |on|
on.message do |event, data|
sse.write("event: #{event}\n")
sse.write("data: #{data}\n\n")
end
end
rescue IOError
logger.info "SSE Stream Closed"
ensure
redis.quit
sse.close
end
end
This is a basic example to describe the idea, when events controller action gets incoming request, the connection is hijacked and pushed to processing in a separate thread, then returning response to free up the currently busy thread. This example is using Redis pub/sub to publish (create message endpoint) messages and subscribe (private method). For the real world implementation one have to store all incoming SSE connections in a global array, and using Ruby Async to broadcast to those connections.
As mentioned before, currently there are no solutions similar to ActionCable or MessageBus to work with SSE in Ruby projects, so most of the functionality will have to be implemented from scratch. But considering SSE benefits, it’s a good option to consider for real-time communication.
Conclusion
It is not quite obvious which way one should choose when there’s a need of real-time features in a Ruby app. The main takeaway is that there is no one-size-fits-all solution for real-time communication, and you should choose the right tool for the job based on your project requirements. And better to do it before you start building your app, so you can avoid refactoring and rewriting the code later. These days in Ruby (and Rails) world it may seem that the only way to go is websockets, but in fact WS is not the only option and, in most cases, can be an overkill solution (mostly because of complexity), which is also not as reliable as one could want.
References
- Dementyev, Vladimir. “AnyCable: Action Cable on Steroids.” Evilmartians, 20 Dec. 2016, evilmartians.com/chronicles/anycable-actioncable-on-steroids.
- Saffron, Sam. “WebSockets, Caution Required!” WebSockets, Caution Required!, 29 Dec. 2015, samsaffron.com/archive/2015/12/29/websockets-caution-required.
- O’Riordan, Matthew. “Rails ActionCable - the Good and the Bad | Ably Blog: Data in Motion.” Ably Realtime, 25 Oct. 2022, ably.com/blog/rails-actioncable-the-good-and-the-bad.
- Loreto, S., et al. “RFC 6202: Known Issues and Best Practices for the Use of Long Polling and Streaming in Bidirectional HTTP.” RFC 6202: Known Issues and Best Practices for the Use of Long Polling and Streaming in Bidirectional HTTP, Apr. 2011, www.rfc-editor.org/rfc/rfc6202#section-2.2.
- Chumakov, Anton. “Rails. Processing SSE connections without blocking server threads using Rack Hijacking API”, 21 Jan 2019, blog.chumakoff.com/en/posts/rails_sse_rack_hijacking_api